
API Mock vs. Simulation
What is the difference between an API mock and a simulation, and why does that matter?
Identifying and validating an API Design starts by defining and testing its capabilities. So, how do you test an API's capabilities without first having to implement them? If your guess is that you can use an API mock, then you're totally right. One of the goals of a mock is to let you interact with an API without having to implement it. With a mock, you can easily show a stakeholder what interacting with the finished API would feel like. In a way, an API mock acts as a prototype. But it can be much more than that. It can help developers write functional tests against an API that doesn't exist yet. And implement client code for things like Web and mobile frontends. However, API mocks lack the dynamic nature that a real API offers. Since all data is previously generated, a mock only works well when all you want to do is read. If you want to be able to manipulate data by creating it, updating it, and even deleting it, you need something else: an API simulation. Keep reading to understand the differences between an API mock and a simulation, and what the available solutions are for each case.
This article is brought to you with the help of our supporter: Speakeasy.
Turn your API platform into an AI platform with Gram by Speakeasy. Create tools from OpenAPI, curate into custom toolsets, and deploy hosted MCP servers.
Nothing can replace the interaction with a real API. Not until you connect with a simulation of the API, that is. Simulations let you, as a consumer, communicate with specific parts of the API, or even the whole thing. It's as if you were making requests to the real API. So, simulations don't necessarily need to guarantee that all API features are available. Only the ones that consumers want to use. You can, for example, simulate all operations but leave behind all authentication. Or, you can simulate all reading operations and forgo anything that manipulates data. What's important in a simulation is that it's well-suited to the use cases it aims to support. One of those use cases is integration testing, which can be fulfilled with API mocks. Another use case is application prototyping, which needs one or several full API simulations. Let's explore the alternatives, starting with API mocks, to understand how to pick a solution.
API mocks have been around for a while. If I remember correctly, mocking got popular with the growth of one of the early API testing tools: SoapUI. While it began around 2005 as a way to test and mock SOAP APIs, it also ended up supporting REST. Since then, many other tools and solutions have been created. Among those are open-source solutions like Prism and WireMock, and commercial products like Mockfly and Mockoon. If, from the outside, they all look similar, there are a few features you can use to find their differences. One is the ability to create mocks based on an API definition. This is what we call spec-based mocking. Another one is request validation, or being able to validate all requests against the API definition. Then you have latency, which is the ability to simulate latency so you can test different conditions. And finally, there is dynamic response generation, which is what makes mocks credible, after all. There are even more features, but these are enough to give you a good comparison. Let's look at a table to make it easier.
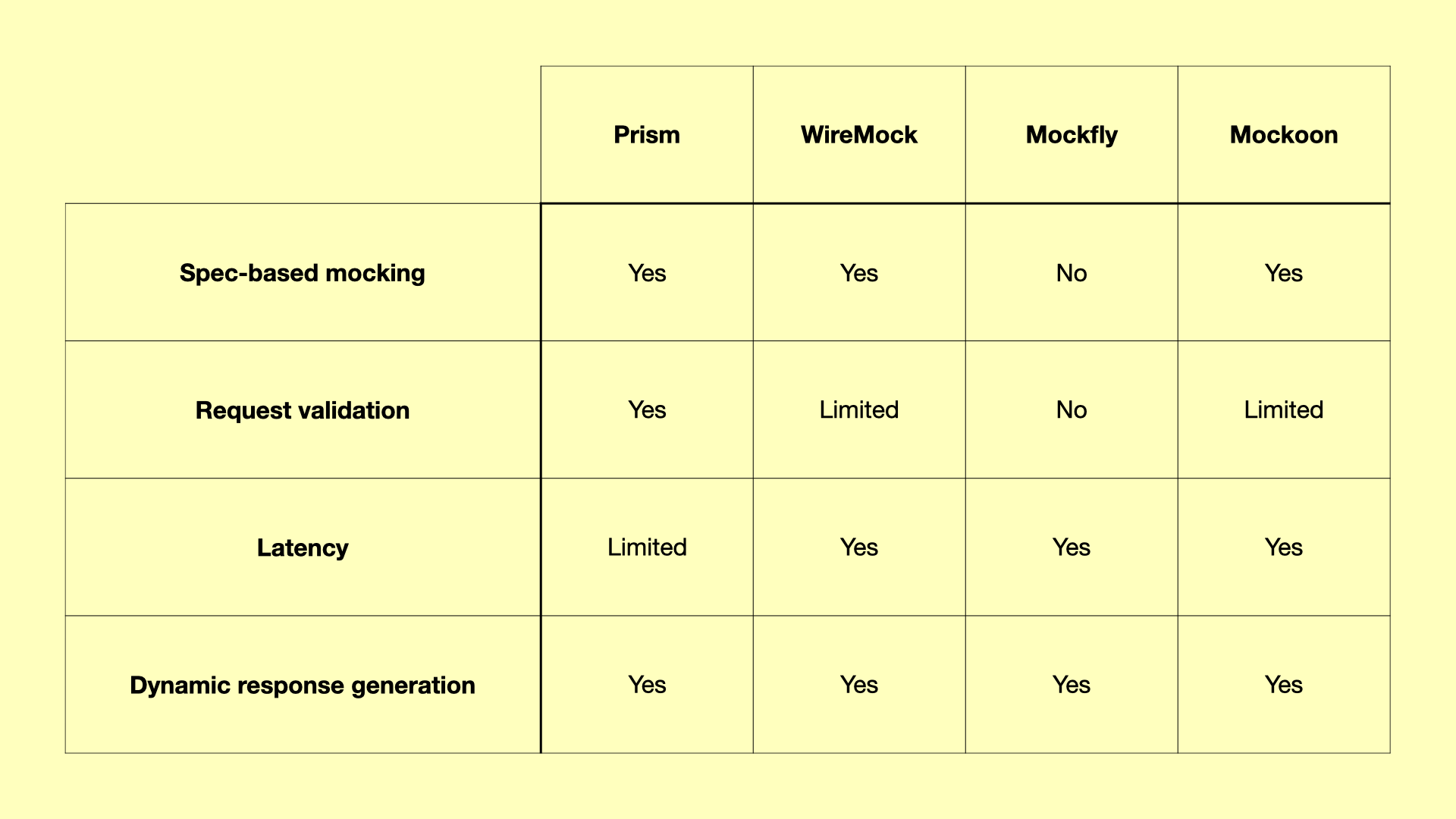
The interesting thing (at least to me) in this comparison is that all API mock solutions are very similar in the features they support. However, there's one thing that I didn't mention. Dynamic response generation is the first step toward a full API simulation. Even though all solutions support it, only one goes beyond and offers what you can call data persistence or stateful operations. It's the ability to simulate the behavior of operations that mutate data and persist the information between requests. Suppose you have an API that lets consumers list articles but also has operations for creating, updating, and deleting. In a "traditional" mock server, if a consumer makes a request to the article creation operation, it will return a successful response, but it won't update the items on the list of articles. On the other hand, on a persistent operation, if a consumer creates a new article, that article is stored and becomes part of the list response. Similarly, if a consumer deletes an article, it will disappear from the list response. As you can see, persistence alone is a major step toward a full API simulation.
Another major step to full API simulation is the ability to add custom logic to each operation. With it, you could, for instance, add specific request validation rules. Or, you could manipulate a request input and format it in a way more suitable for storage. Or, you could perform a calculation on the request input parameters and serve the appropriate response. Altogether, adding custom logic to any operation makes an API simulation feel almost like the real thing. Yes, it's true that someone needs to write the logic. However, the outcome you get makes it all worth it.
Altogether, transitioning from a traditional mock into a full API simulation shouldn't be too hard. If you pick the right solutions and are able to extend them, you're halfway there. With that, you can offer your stakeholders something that feels almost like the real API so they can give you the feedback you need. Then, you can iterate quickly until you reach the final solution.