
Hitching AI to APIs Locally
How hard is it to program an AI agent without writing any code?
Successful AI agents are those who know how to use APIs natively. Many tools have been experimenting with approaches to connecting AI to APIs. Not many have been successful. The right mix of AI and APIs needs to be fine-tuned to specific needs. The best—and easiest—way to achieve it is to experiment locally until you're successful. But how can you do that without having to write much code?
This article is brought to you with the help of our supporter, n8n.
n8n is the fastest way to plug AI into your own data. Build autonomous, multi-step agents, using any model, including self-hosted. Use over 400 integrations to build powerful AI-native workflows.
I've been exploring the connection between AI and APIs for a while. I believe that APIs are the ingredient AI needs to perform tasks on behalf of users. However, a simple task, such as booking a train ticket, can't yet be delegated to an AI agent successfully. There's definitely a missing link between AI and APIs. And you need to find that link and make it work to take full advantage of what AI has to offer.
A good way to understand how something works is to run experiments. That's exactly what I've been doing with AI. My attempts usually involve writing specific code that interacts with one of the AI APIs compatible with OpenAI. Then, I try to extract meaning out of what the AI can decipher. And, with the meaning—or intent—I try to make requests to specific APIs. Even though this is an interesting approach, it's time-consuming because I have to write code every time I change my mind.
I prefer to run experiments quickly, so I started using low-code tools such as Zapier and n8n. With Zapier, I'm able to automate the retrieval of information and the requests to third-party APIs. However, I can't run it locally. By locally, I mean running it on my own laptop but also inside an instance that I control. Locally also means being able to tweak how things work without depending on any specific external service.

One tool that lets me achieve all that is n8n. At least, that's what they announced in August 2024. The promise is that you can get your self-hosted AI starter kit just by following a simple set of instructions. In the announcement, they mention the "starter kit is designed to help you get started with self-hosted AI workflows." They're cautious to highlight that the kit isn't "fully optimized for production environments" as its goal is to offer a local experimentation environment.
My first step was to make sure I had all the prerequisites to run the AI starter kit. Since I'm running an M2 Mac, I don't have an NVIDIA GPU, which is something that makes AI run faster. I need to run Ollama on my own machine and make sure it's working with the model I choose. The second thing I need is a copy of Docker running on my laptop, and I'm good to go. I followed the instructions for Mac users and proceeded to clone the repo.
After running docker compose up, I had a copy of n8n running locally. I opened the included "Demo workflow" and proceeded to change the URL of my Ollama server to http://host.docker.internal:11434/, my local Docker host. The first thing I tried was to chat with the model running on Ollama, llama3.1. I started with a simple "Hello world" just to see what would happen. After about 5 seconds—I'm running it locally, so it's slow—I got a response from the model.

Then, I started experimenting with building a workflow that would call external APIs to perform actions based on my intent. I used the Tools AI Agent, which can detect my intent and pick the right tool to use. In this case, tools can be external APIs, other n8n workflows, and even JavaScript code. I first tried something simple: connecting the Tools AI Agent to Wikipedia. Then I asked the chat model something it wouldn't know without consulting Wikipedia: recent population statistics. Since the model only has access to historical data, it doesn't know how to answer questions about recent events.
My question was, "What was the population of New York City in January 2024?" Without access to Wikipedia, the answer was a vague declination, explaining that January 2024 is, from the model perspective, still in the future. However, after connecting Wikipedia to the Tools AI Agent, the answer was accurate. This is starting to get interesting. What else can I do with it?
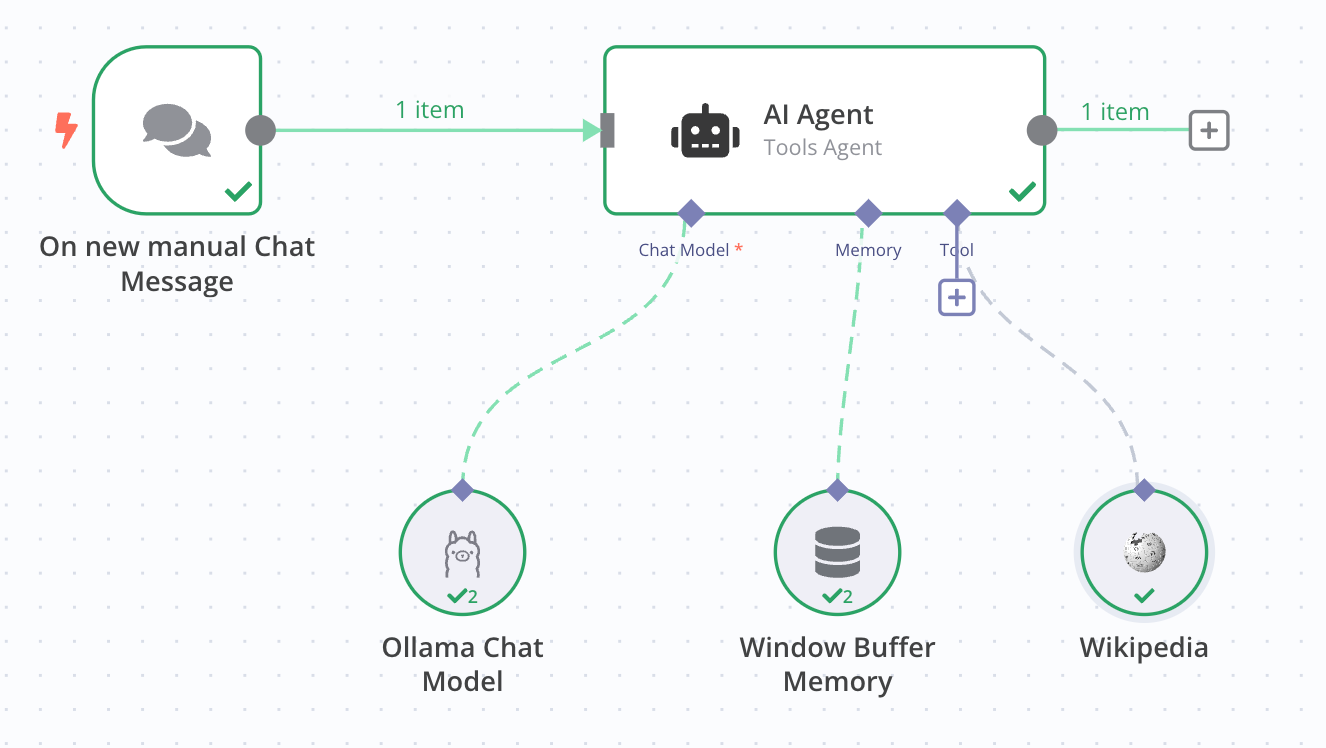
The second thing I tried was connecting the SerpAPI to the Tools AI Agent. This time, I wanted to try asking for something more recent, such as weather information. I asked, "What is the current weather in New York City?" It worked flawlessly. I also tried to ask something more elaborate but still related to the current weather. I asked the chat model to suggest clothing for going out. Since it already knew that it wasn't raining, it told me to wear a sweater, a light jacket, and some comfortable pants and sneakers.
Getting from here to interacting with other APIs is only one step away. You can easily create a new workflow and connect it to the Tools AI Agent as a tool. It will then attempt to execute the workflow whenever it feels appropriate and retrieve the information it needs or perform the action based on your intent. I'll be experimenting more, for sure, now that I know I can do it locally.
Something else interesting is that the Tools AI Agent is based on LangChain. As such, it can infer what I want—my intent—and then find the best tool to call based on the ones available. According to the documentation, "LangChain provides a standardized interface for tool calling that is consistent across different models." This means I can switch from my local Ollama setup to using an external AI provider such as OpenAI or Mistral without having to change anything on my workflow.
While I still can't use this setup to book train tickets from within an AI chat, I feel we're very close to being able to do it. I will definitely be experimenting with different train ticket APIs and see how I can connect things together. Stay tuned to see where I'll be able to go with this approach.